Introduction: Racecar Game With Pygame Zero and Machine Learning




I have always been little too fond of computer games. I pulled my first all-nighter while playing Age of Empires with my friends.
Age of Empires is a strategy game where you play against a computer or a human to establish and defend your colony. I always wondered about the optimum strategy and how computer just crushes you when you play with in in hard mode.
Through this instructable, lets take behind the curtain look at one really simple game i.e. a racecar game where the objective is to navigate bunch of barriers using a car without colliding with them and also create a computer agent that plays this game using machine learning.
Lets get started.
Supplies
Step 1: Video
Here is the link to video that explains this instructable, if you are a video guy.
Step 2: Table of Contents
We will proceed through this instructable as follows.
- Introduction to Pygame Zero i.e. the utility in which we will create our game,
- Create basic game where we can play the racecar game,
- Introduction to Reinforcement learning and
- Create an agent that plays the game on its own.
Step 3: Introduction to Pygame Zero


We will create this game in relatively easy to learn programming language called python and in particular something called pygame-zero which is very basic programming interface for creating games in python.
A typical game loop revolves around 3 main components until it ends-
- Input processing,
- Updating internal parameters and
- Rendering updates on screen.
Pygame zero has 2 function that fulfill these tasks called draw() and update(). Draw() is called by pygame zero when it needs to redraw the game window. Update() is called by pygame zero repeatedly 60 times a second and this is where we include our gaming logic.
All the images necessary to create a game for example in our case an image of a race car and barrier as shown in the attached images, should be stored in a folder named "images", parallel to file containing game code.
Also to run a pygame zero code we need to use following command.
pgzrun <filename>
Step 4: Create Basic Game

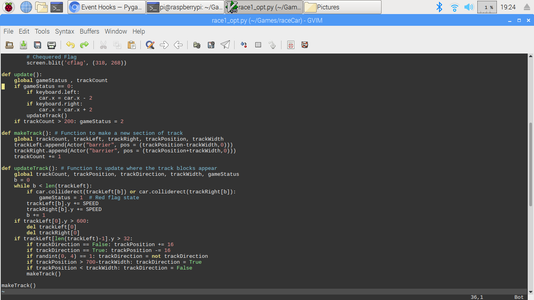
Now that we have some knowledge of pygame zero, lets go ahead with creating the game.
I have attached images and code for quick reference but in order to run this code at you end please make sure to download images from the link in the supplies.
In code, first we define two variables called height and width, that defines the size of our gaming window, then we have speed variable which determines the speed at which barriers approach our actor. After that we set actor's initial position in game window. Following that we have two list variables that store location of left and right barriers, trackCount variable keeps count of barriers crossed by our car without colliding with them. The we have three variables defining track's starting location, its width and a variable that controls the location of next barriers. For example if trackDirection is set to false, next barrier is placed on right to the current barrier and other way round. Finally, gameStatus variable indicates if game is currently in progress or completed successfully which is crossing 200 barriers in our case or resulted in collision with the barrier.
Next, we have draw() that populates game screen with needed characters at appropriate locations. This function also draws red flag on screen if you hit a barrier, this function will also display chequered flag if you cross 200 barriers.
Next, we have update() that takes in user inputs and updates car's location by 2 pixels to left or right.
Next, we have makeTrack() that adds in new barriers and following that we have updateTrack() that sets variable to randomize barrier location and also detect collision with barriers and set gameStatus to game over on collision.
Let's give credit to original creator of this game, who is Mr Mark Venstone.
Before we get to the next segment, have a tea or coffee, down load the code and try playing this game on your machine. Let's take a look at reinforcement learning basics.
Attachments

Step 5: Introduction to Reinforcement Learning








Ok, now you and I know how to play this game but does a computer know how to play this game on its own. At this moment definitely not. We can teach it using something called "Reinforcement Learning".
sidenote - I have numbered attached images at top left corner for easy reference.
Let's take a look at some of the terminology from reinforcement learning world. First, we have agent(image #1), it is the thing that interacts with the environment and it does it using actions i.e. in our case actions can be wither moving left, right or not moving at all(image #3). On taking any action, agent moves from one state in environment to another state. On moving to next state, we give agent a reward, for example if next state leads to successfully crossing barrier we give a reward of +1. If next state leads to collision with the barrier we penalize agent with the reward of -300. But how does an agent decides on which action should it take in its current state, answer to this question is something called "action-value function or Q function". This function tells agent the value of taking an action in any given state, where value of state represents measure of possible future rewards (image #4).
So the job of our agent is to take an action with maximum value(image #5), and it will ride the track without collision. But there is another problem, agent doesn't know action-value function of the environment when it interacts with it at first (image #6). So we use an iterative algorithm, where we initialize action-value function randomly (image #7) and then as we play episodes of our game, we update action-value function such that it converges to true action-value function for this environment(image #4).
Let's take a look at this algorithm in code.
Step 6: Code for Agent That Plays the Game on Its Own


First we obtain the current state of our agent in the environment. For our game, it is distance from few barriers in front. We sample an action based on Q-function, we execute that action to get reward and next state. Based on reward obtained we update our Q-function and this goes on and on and on for quite some time. After running this code for 20hrs. We get quite a descent driver.
Take a look at video in initial steps to look at this driver in action.
That's it. I hope you enjoyed the article and don't forget to vote.
Thanks.
Attachments

Participated in the
Games Contest






